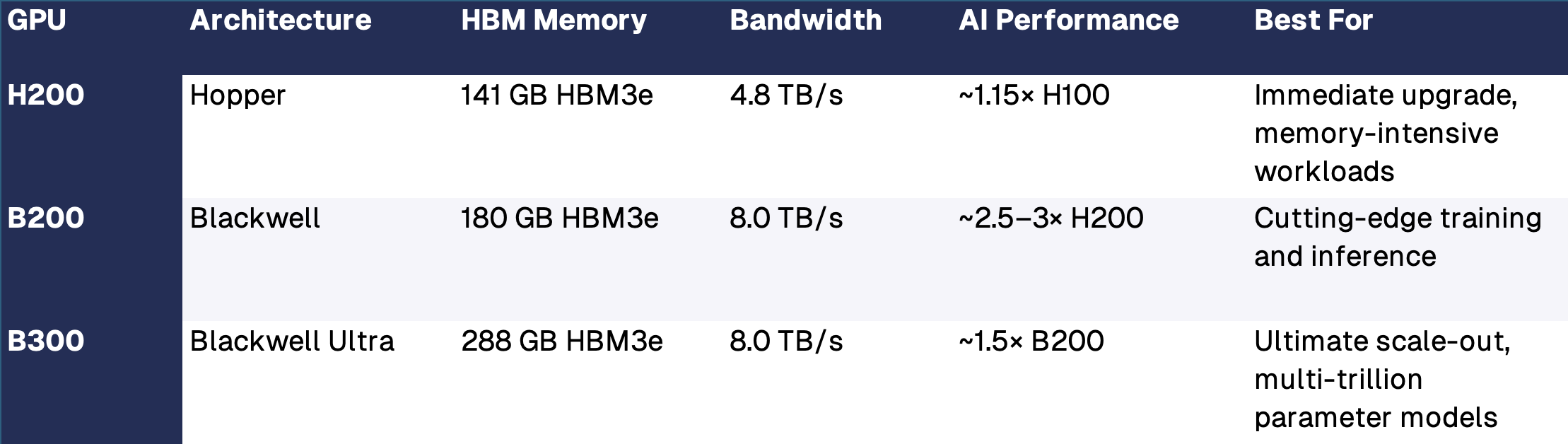
When scaling an AI cluster for large language models (LLMs), high performance computing (HPC), or enterprise AI, your choice of backend network fabric can significantly impact performance, cost, and scalability. Should you choose InfiniBand or Ethernet?
InfiniBand has been the dominant choice for hyperscale AI due to its ultra-low latency and efficient scaling. However, Ethernet is evolving quickly, supported by the Ultra Ethernet Consortium (UEC) and new AI-optimized offerings like NVIDIA’s Spectrum-X platform.
Both networking options currently offer 400G throughput, and 800G hardware is beginning to ship with platforms like NVIDIA B300 and next-gen switches. The right choice depends on your workload size, cluster architecture, and budget.
InfiniBand: High-Performance Interconnect for Hyperscale AI
Throughput: 200–400 Gbps per port, with next-gen 800G systems just starting to ship
Latency: ~1–2 µs, ideal for gradient-heavy training at scale
Native RDMA: Hardware-offloaded, ensuring efficient GPU-to-GPU communication
Deployment: Common in large-scale LLM training and HPC supercomputing environments
Best for: Clusters with 32+ nodes where performance consistency, scaling efficiency, and predictable latency are critical.
Ethernet: A Cost-Effective and Flexible Alternative
Throughput: 100–400 Gbps typical, with 800G Ethernet available from NVIDIA, Broadcom, Arista, and others
Latency: Tuned RoCEv2 delivers approximately 5–10 µs
Ecosystem: Multi-vendor, cost-efficient, and deeply integrated with cloud-native infrastructure
Momentum: Backed by the Ultra Ethernet Consortium and validated by NVIDIA’s Spectrum-X, Ethernet is moving from “good enough” to AI-optimized
Best for: Mid-size AI clusters, inference deployments, and cost-sensitive R&D environments.
InfiniBand vs. Ethernet: Side-by-Side Comparison

GPU Utilization Matters
Your network fabric directly impacts GPU utilization, which drives time-to-train and total cost of ownership. InfiniBand helps sustain high utilization in large-scale clusters by reducing synchronization delays. Ethernet can also deliver strong utilization in smaller or well-tuned environments, but may require more careful configuration to avoid bottlenecks at scale.
Cost and Operational Considerations
InfiniBand often comes with a higher upfront and operational cost, but delivers better performance at hyperscale. Ethernet provides more flexible, cost-efficient options and is better suited for smaller clusters or hybrid deployments. Organizations with strong DevOps and cloud-native infrastructure can often make Ethernet work well for many AI workloads.

InfiniBand vs Ethernet cost and performance comparison for AI infrastructure
When to Choose Each Fabric
The market is evolving toward a dual-path future: InfiniBand for hyperscale performance, and Ethernet for broad accessibility and cost-effective AI compute.

Strategic Takeaways for LLM Training
- InfiniBand = predictable scaling at hyperscale
Still the top choice for GPT, LLaMA, Claude, and multi-billion parameter training - Ethernet = cost-efficient scale
Viable for enterprise AI, inference, and R&D with 800G platforms - The future is dual-track: InfiniBand for hyperscale, Ethernet for the majority of AI clusters
How Arc Compute Helps
At Arc Compute, we tailor GPU and networking solutions to each client’s unique scale and goals. We assess workloads, architecture, and budget to recommend the right interconnect.
- InfiniBand Superclusters: Built using NVIDIA HGX with 400G/800G Quantum-2 fabrics
- Ethernet AI Clusters: Cost-optimized deployments using Spectrum-X and other 800G-capable platforms
Example: In Boson AI’s 65-node H100 training cluster, we implemented 400G InfiniBand using Quantum-2 switches, delivering high utilization and predictable scaling.
Planning your next build? Talk to our team about the right interconnect for your needs.
Frequently Asked Questions
Q1. Which is better for LLM training?
For clusters with 32 nodes or more, InfiniBand typically provides better latency and scaling. For smaller or experimental setups, Ethernet may be sufficient.
Q2. Does NVIDIA support Ethernet for AI?
Yes. NVIDIA is a founding member of the Ultra Ethernet Consortium and has released AI-optimized Spectrum-X 800G Ethernet switches.
Q3. How do performance characteristics differ?
InfiniBand has lower latency (~1–2 µs) and better performance consistency at scale. Ethernet with RoCEv2 offers ~5–10 µs latency and can be tuned for AI workloads.
Q4. Is Ethernet ready for AI workloads?
Yes. With 800G switches, growing vendor support, and UEC standards, Ethernet is increasingly being adopted in AI training and inference environments.
Final Thoughts
If you’re building a hyperscale LLM training cluster, InfiniBand remains the gold standard for performance and reliability. But for most AI deployments, including inference, R&D, and mid-size training, Ethernet is now a viable, cost-effective option.
Smart infrastructure starts with smart choices. Arc Compute is here to help you design the interconnect that best supports your AI goals.